Google ships Gemini 3.1 Flash TTS with 200 audio tags and scene direction for expressive AI speech

Google released Gemini 3.1 Flash TTS on April 15, 2026, a text-to-speech model that introduces inline audio tags, scene direction, and speaker-level audio profiles as first-class controls for AI-generated speech. The model ships with 30 prebuilt voices, supports 80-plus languages, and is available in preview through the Gemini API, Google AI Studio, Vertex AI for enterprises, and Google Vids for Workspace users, according to the Google DeepMind blog post published the same day.
What Gemini 3.1 Flash TTS delivers
The headline feature is a system of 200-plus audio tags that developers embed directly in input text using square bracket notation. Tags like [whispers], [excited], [sarcastic], and [laughs] trigger changes in vocal delivery at the exact point they appear in the transcript. The system also supports pacing and action modifiers such as [sighs], [cough], and [shouting], per the Gemini API speech generation documentation.
Beyond individual tags, Google introduces three layers of structural control:
- Audio Profiles define a character’s core identity and archetype, setting a baseline voice personality.
- Director’s Notes specify performance guidance for style, pacing, and accent, similar to stage direction in a screenplay.
- Scene Direction establishes the physical environment and emotional context, which shapes how the model interprets the transcript.
The model supports native multi-speaker dialogue with up to two speakers per generation, each assigned their own voice and audio profile, per the Gemini API documentation. This makes it possible to generate podcast-style conversations or dramatic scripts in a single API call without stitching separate generations together.


Listen: Gemini 3.1 Flash TTS samples
Three samples generated with the Gemini 3.1 Flash TTS API on April 18, 2026, demonstrating audio tags and expressive control.
Sample 1: Neutral narration (voice: Kore)
Sample 2: Expressive with audio tags [whispers] → [excited] (voice: Puck)
Sample 3: Scene direction with mood shifts (voice: Charon)
Technical specs
Output is PCM audio at 24,000 Hz, mono, 16-bit, returned as base64-encoded inline data, per the API documentation. The model has a 32,000-token context window and does not support streaming, which makes it suited for pre-rendered content rather than real-time voice agents. The 30 prebuilt voices each carry a tonal descriptor (for example, “Kore, Firm”), and language support covers 80-plus languages with BCP-47 locale codes. All generated audio carries an inaudible SynthID watermark for AI provenance tracking, per MarkTechPost on April 15, 2026.
Benchmark position
The model reports an Artificial Analysis TTS leaderboard Elo score of 1,211, per MarkTechPost on April 15, 2026. For context, this positions it as Google’s most natural and expressive speech model to date, though direct Elo comparisons with ElevenLabs and Cartesia Sonic require caution because Elo scores on the Artificial Analysis leaderboard depend on the voting pool and evaluation methodology at the time of measurement.

Pricing and availability
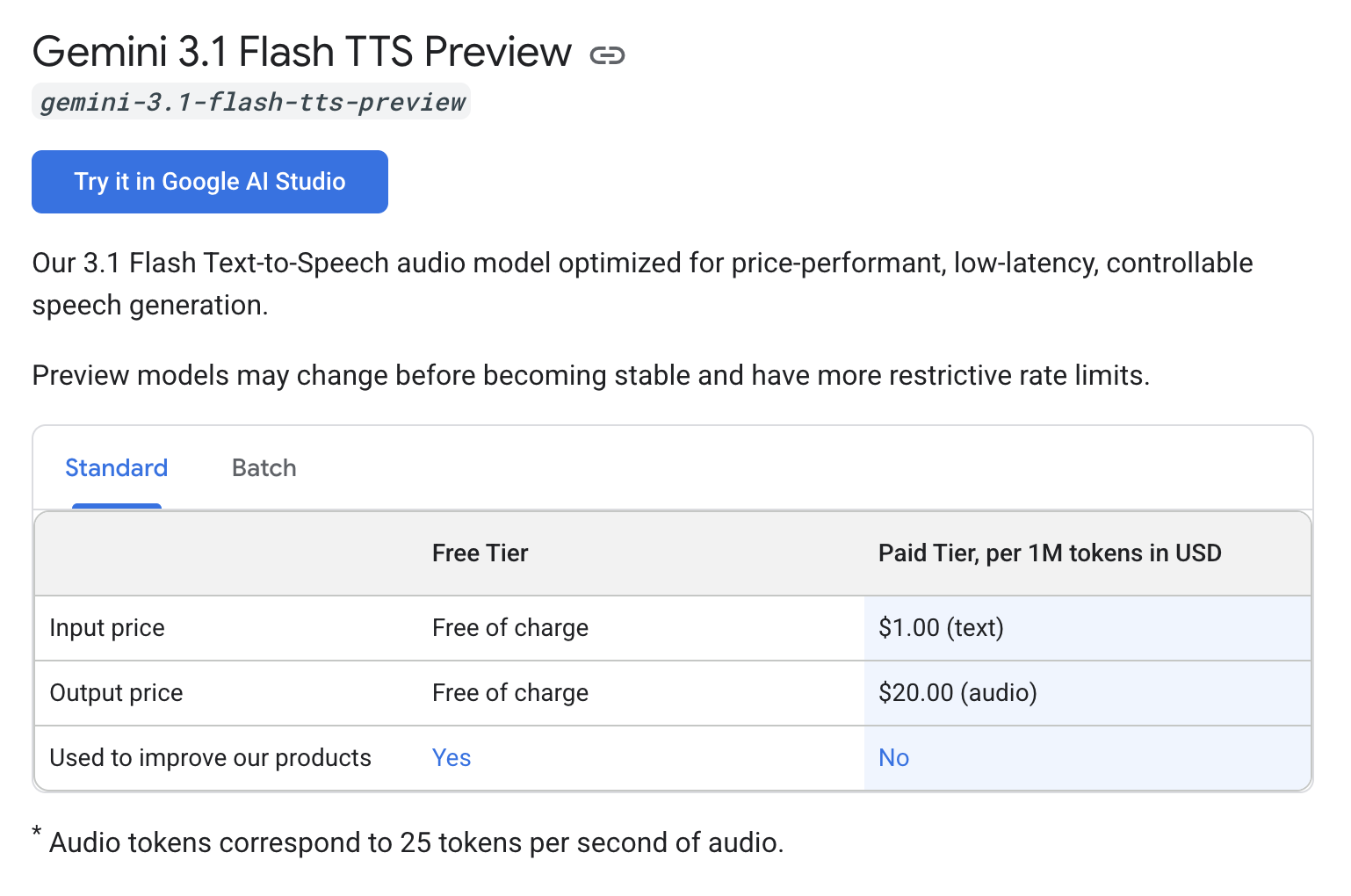
Gemini 3.1 Flash TTS is priced at $1.00 per million input tokens (text) and $20.00 per million output tokens (audio) on the paid tier, with a free tier available, per the Google AI developer pricing page on April 16, 2026. Audio tokens correspond to 25 tokens per second of generated audio, per the same page, which makes the per-minute cost for output audio roughly $0.03 per minute at the paid tier (25 tokens times 60 seconds divided by 1,000,000 times $20). This positions the model at a roughly two times premium over Cartesia Sonic 3 at approximately $0.006 per minute and at parity with ElevenLabs Flash v2.5 at approximately $0.015 per minute, depending on input text length.
| Provider | Model | Pricing model | Rate | Notes |
|---|---|---|---|---|
| Gemini 3.1 Flash TTS | Per token | $1.00 in / $20 out per 1M tokens | Preview, free tier available, no streaming, 80+ languages | |
| Gemini 2.5 Flash TTS | Per token | $1.00 in / $20 out per 1M tokens | Previous generation, same rate | |
| ElevenLabs | Flash v2.5 | Per character | $0.06 per 1K chars (Flash) | 100-200ms TTFB, streaming |
| Cartesia | Sonic 3 | Per credit | ~$0.006/min | 90ms TTFA, 40ms Turbo, streaming |
| Deepgram | Aura-2 | Per character | $0.030 per 1K chars | Sub-200ms TTFB, streaming |
| OpenAI | TTS-1 | Per character | $15 per 1M chars | HD variant at $30 per 1M chars |
TTS pricing comparison as of April 2026
Google Vids integration
The same day, Google Workspace announced that Google Vids now uses Gemini 3.1 Flash TTS for AI voiceovers, with 30 new conversational voice options across 24 languages, according to the Google Workspace Updates blog on April 15, 2026. Sixteen new languages were added: Arabic, Bengali, Dutch, Hindi, Indonesian, Marathi, Polish, Romanian, Russian, Tamil, Telugu, Thai, Turkish, Ukrainian, and Vietnamese. Users can add emotional instructions like “Read this like you are excited” or bracket-based pacing like “This [pause] is amazing” directly in the voiceover script.
Why it matters
Most TTS APIs today offer a voice selector and a text input. Gemini 3.1 Flash TTS adds a third dimension: a structured prompt that describes the scene, the characters, and the performance, alongside 200-plus inline tags that modify delivery word by word. This is the first major TTS model from a hyperscaler to ship scene direction and audio profiles as native API primitives rather than post-processing workarounds.
The no-streaming limitation and the 32,000-token context window mean the model is not yet suited for real-time voice agents, where Cartesia Sonic 3 (40ms TTFA) and ElevenLabs Conversational AI dominate. But for pre-rendered content, audiobooks, podcasts, video narration, and Google Vids voiceovers, the control surface is the deepest available from any single API call as of April 2026.
Pricing holds at $1 per million input tokens and $20 per million output tokens, the same rate as the predecessor Gemini 2.5 Flash TTS. Google kept the price flat while adding the audio tag, scene direction, and audio profile controls, which effectively delivers a capability upgrade at constant cost.
- Google DeepMind, "Gemini 3.1 Flash TTS: the next generation of expressive AI speech," April 15, 2026. deepmind.google
- Google AI for Developers, "Text-to-speech generation (TTS)," April 2026. ai.google.dev
- Google AI for Developers, "Gemini API pricing," April 2026. ai.google.dev
- Google AI for Developers, "Gemini 3.1 Flash TTS Preview model page," April 2026. ai.google.dev
- Google Workspace Updates, "New more expressive AI voiceovers in Google Vids, and 16 additional languages, powered by Gemini 3.1 Flash TTS," April 15, 2026. workspaceupdates.googleblog.com
- Google Cloud, "Gemini 3.1 Flash TTS on Google Cloud," April 2026. cloud.google.com
- MarkTechPost, "Google AI Launches Gemini 3.1 Flash TTS: A New Benchmark in Expressive and Controllable AI Voice," April 15, 2026. marktechpost.com
- Logan Kilpatrick (Google), "Introducing Gemini 3.1 Flash TTS (X post)," April 15, 2026. x.com
- Google AI Developers, "Introducing Gemini 3.1 Flash TTS (X post)," April 15, 2026. x.com
- Google Cloud, "Gemini-TTS documentation," April 2026. docs.cloud.google.com
- Google Cloud, "Vertex AI Pricing," April 2026. cloud.google.com
- Engadget, "Google's new text-to-speech can switch languages on the fly," April 2026. engadget.com
- Artificial Analysis, "TTS Leaderboard," April 2026. artificialanalysis.ai
- ElevenLabs, "API Pricing," April 2026. elevenlabs.io
- Cartesia, "Sonic 3 product page," April 2026. cartesia.ai